Title here
Summary here
AMD's agentic AI workflow, Samtec's new oHFM standard, and Lattice's case for AI on the edge
May 19, 202611 minutes

Last week I was at FPGA Horizons US East, the second of these events but the first to be held in the US. I had a fantastic time, met a lot of interesting people and learned a lot about where things are heading in the FPGA world. While it’s still fresh on my mind, I wanted to write up some of the things that I took away from the talks and the workshop. This wont be comprehensive, I’ll be focused on what stood out to me.
AMD’s Martin Charron kicked things off with a keynote talking about the early Xilinx FPGAs and the trend towards these powerful heterogeneous devices that we see today. One of the first things he said was how nice it was to be in “a room full of people actually who knew what an FPGA was”. I think that hit home for everyone and we owe a lot of credit and gratitude to Adam Taylor and Louise Paul for creating and organizing this event that brings the FPGA community together.
The next talk I saw was Low Power FPGAs and Compact High Accuracy AI Models Enabling Smart Sensing by Hussein Osman of Lattice. The idea of this talk is that we’re trending to a world with more sensors that generate data that we would like to feed to AI models. Ideally, we want the AI processors to be running next to the sensors (ie. on the edge device vs on the cloud) but if we don’t design the interfaces and distribute the workload intelligently, we wont get optimal performance. Lattice proposes two basic architectures: (1) use an FPGA to interface with the sensors, perform minimal processing before passing the data to the AI processor or SoC, or (2) use an FPGA to run the AI inferencing and then pass only metadata to a low-power SoC. In both cases, we are basically offloading work to an FPGA which is generally more power efficient, has lower latency and can handle higher bandwidths than a typical GPU or SoC. I thought it was particularly interesting that these FPGA-based AI implementations generally had a lower latency than the equivalent GPU implementation. That makes them valuable for things like self-driving cars where the time to react is a critical design factor. One of the other advantages is the fact that FPGAs can be reprogrammed, so you can easily change the model - a huge advantage when you consider how fast these models are developing.
Later on I had a talk to Hussein at the Lattice booth. I asked him how the Lattice FPGA AI models compared in performance and power consumption to external AI accelerators like the Hailo-8. They’re positive that these FPGA based models are more power efficient than GPU models. However when it comes to AI accelerators, they haven’t done any benchmarking or comparisons yet. I have a feeling about the answer to this question already. FPGA-based AI processors probably have a latency advantage over most devices; they can interface directly with the sensor (say a MIPI image sensor) and they don’t have to shuffle data back and forth to an external memory. This is not to say that FPGAs would produce the highest performance, or even the highest performance per Watt - that’s something that needs to be benchmarked. My guess would be that AI accelerators like the Hailo-8 are probably going to give you the most inference TOPS per Watt. BTW, if you’re interested in AI accelerator benchmarking, I suggest you checkout Mario Bergeron’s blog - he is one of the biggest experts in this growing field of interest.
Next talk: SGET Open Harmonized FPGA Module(oHFM) is Here! with Matthew Burns from Samtec. Hard to make this choice over the Efinix talk on AI on the Edge, but I can’t help seeing this take off like FMC (VITA 57.1) did more than a decade ago. So this new standard called oHFM (Open Harmonized FPGA Module) is on a mission to do for SoMs (System-on-Modules) what FMC did for FPGA I/O add-on cards. FPGA/SoC-based SoMs have been around for quite a few years now and they’ve really changed the way us designers go about designing new projects. They basically allow us to design new FPGA/SoC products faster for less NRE cost and less risk. But vendors never collaborated on how these SoMs should be designed. Everyone basically has their own offering, with their own connectors and their own form factor. Between vendors, nothing is interchangable, aka vendor lock-in. If you ever try to switch vendors, you have to redesign your carrier board, thermal management, housing, etc. oHFM standardizes SoM design so that you can design the product once, and you’re not locked into one vendor who might not always have stock on hand, or who might not always be the most price competitive.
Some interesting points. The oHFM SoMs come in four sizes (S, M, L and XL) and each of those sizes has an extended version that is wider to accommodate more components. They come in two versions: a solderable version (oHFM.s) and a connector based version (oHFM.c).
The solderable version, shown below, creates a lower-cost SoM because it doesn’t have connectors. However that comes with a compromise on throughput, since the PCB-to-PCB interface doesn’t support the highest frequencies (like 112Gbps PAM4) and it has a lower pin-count than the connector interface.
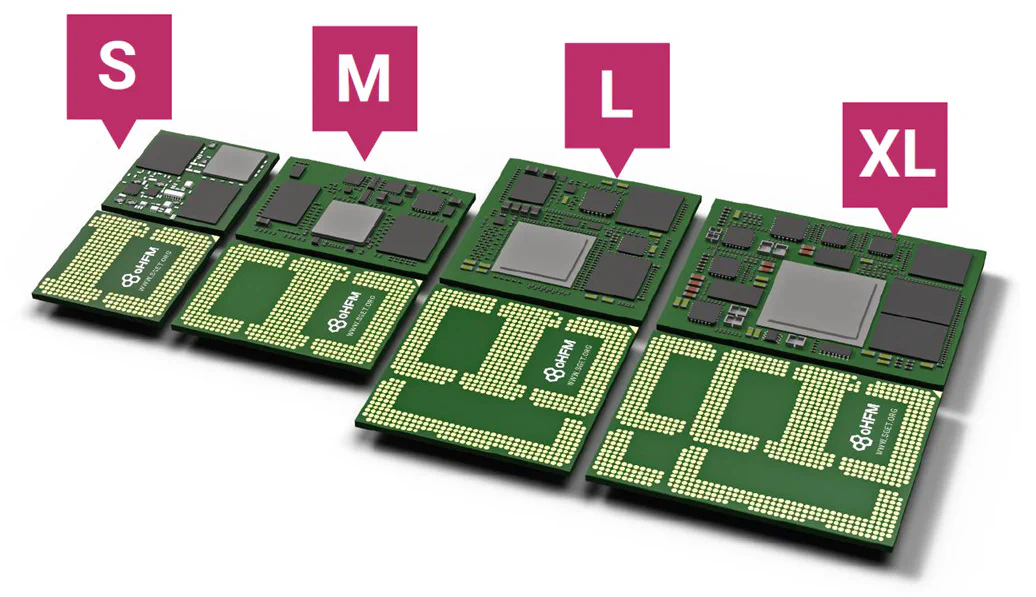
The connector based version, shown below, uses dense high-performance connectors from Samtec for a pluggable SoM that offers a higher pin-count, speed and throughput. In the image below you can see that there are two types of connectors. The smaller SoMs have connectors that can support up to 64Gbps PAM4 signals. The larger SoMs have those same connectors plus larger connectors that can support up to 112Gbps PAM4. For comparison, FMC/FMC+ connectors support up to 56Gbps PAM4.

I think oHFM is a brilliant idea and I’m keen to hear more news about it. If you want to know more about the standard, you can read about it here: SGET oHFM
For me, AMD’s workshop on AI Agentic workflows was the highlight of FPGA Horizons US East 2026. If you read my last post on agentic AI then you know that I’m confident that agentic AI is going to completely change the way FPGA developers work. AMD clearly has a big role to play in this transition so I was happy to see that they have made some good decisions on how to integrate AI workflows into their tools.
AMD has basically done two things: (1) created a Model Context Protocol (MCP) server to provide AI agents with access to AMD documentation, and (2) created a series of agent skills that provide procedural instructions for common FPGA/SoC development tasks that are done through the tools.
If you have already started using agentic AI like Claude Code with the AMD tools you will know that we are already able to get a lot of work done without an MCP server and without agent skills - so what value do they add? The answer is that they help us to get more deterministic behavior out of the AI agents, which are inherently probabilistic. To me, a good metaphor to remind us of the need for deterministic behavior is high-level synthesis (HLS). In HLS, we put C code in and get HDL out. When we update the tools, we hope that the same C code generates the same HDL output, but it sometimes doesn’t, causing unexpected problems down the line. The same problem can be found when using AI tools. The AI model changes, is retrained, gets “improved”, and the quality of its work changes; not always for the better. The MCP server and agent skills are there to ensure that the AI agents always work using the correct information for the version of the tools that they are driving, and that they always follow the same procedural “best practices” for the task that they are being asked to complete. I’m not saying that all this makes the AI deterministic, it just makes the AI work in a way that is somewhat more deterministic, more repeatable.
If I speak from my experience with Claude Code, out-of-the-box (ie. from its training alone), it already seems to have a good working knowledge of the AMD tools (Vivado, Vitis and PetaLinux) including how to drive them with Tcl and Python. However, it is always overconfident in its own knowledge of the tools, even when that knowledge is based on an older version of the tools. An AI model’s training data is rarely going to include AMD’s very latest tool releases, and it’s never going to be complete or comprehensive. But the AMD MCP server can be all of those things, and that’s why we can expect to get significantly better results using AI with the MCP server vs AI without it.
To talk more about agent skills, these are important because they lock down step-by-step instructions for tasks that we often need to perform when designing for FPGAs and SoCs. A good example, one which we looked at in the workshop, is fixing a timing closure problem. I’ve fixed my share of timing closure problems, but I wouldn’t say that I’m an expert at it. From one timing issue to another, I feel like I’m starting over again, that I don’t have a real method or strategy for handling these things. Now imaging just saying to the tools “the design doesn’t pass timing can you please fix it”. That prompt, and other similar ways of saying that, would be flagged by the AI agent as something that it has a skill for. It would then look into its set of agent skills and find the “timing closure skill”. That skill would then guide it through a procedure, designed by FPGA engineers at AMD, to methodically and strategically find a solution to close timing, and do it quickly. We saw this in action during the workshop and I think that everyone in the room was blown away.
Another useful thing about the agent skills is that you can customize them according to your workflow. So let’s say that at your company there is a set of documentation requirements that must be met each time that you create a new IP. Well you can lay down these requirements into an agent skill so that when you say “create an IP that does so-and-so”, it will recognize the fact that you want it to create an IP and pick up the corresponding skill to ensure that it is also creating all the needed documentation specified by your procedure.
As I mentioned, the agentic AI workflow has already been possible for a while now since Vivado/Vitis/PetaLinux tools have Tcl/Python interfaces - however let’s talk specifically about the MCP server and the agent skills. We were told in the workshop that these things would be available in an early access lounge in “a few weeks time” before being officially released. No paywall: the workflow will support all tool licenses including the ML Standard license (the free license). It will support current and older tool versions, although they haven’t tested it past a certain version. They did also mention that they were working on adding an AI agent extension to the tools which would only be available in a future version.
In the workshop, we used the agentic AI workflow in VS Code with a Claude Code extension installed. We followed through a few Jupiter notebook based demos containing a series of natural language prompts that we fed to Claude Code. In a real-world use case, you could use VS Code or you could just use a bash terminal, it’s really up to you and your preferred work environment. If you like working in the Vivado GUI, from the terminal you can ask the agent to open the GUI and perform work within the GUI, for example “open the Vivado GUI and create a block design that contains this and that”. You’ll see the Vivado GUI open up and the work being performed in the GUI, much like you would if you had pasted a series of Tcl commands into the GUI’s console window.
It’s probably obvious to you by now that this agentic AI workflow is model agnostic - you’re not limited to using Claude Code, you can use Codex instead or even a locally run model. In fact, at the end of the workshop we got to try out the workflow using a locally run AI model. I got the feeling that privacy and confidentiality was a big concern for a lot of people, so being able to use a locally run model was of huge interest. My experience with the local LLM was a bit of a let-down however. The main problem being that it was painfully slow.
Overall, I really enjoyed the workshop and I got the feeling that most people were genuinely blown away with how easy it was to use and how powerful it was. Kudos to Goutham Pocklassery and Nabeel Shirazi for running such an amazing workshop.
What a fantastic event! I came away from this event feeling energized and happy to know that us FPGA people finally have a place we can connect and share ideas. I’ll be going to the next FPGA Horizons event in London this October and hosting a booth for my company Opsero displaying our FMC cards and a couple of interesting live demos. Thanks again to Adiuvo, Adam Taylor and Louise Paul for creating this amazing event!